⚠ 转载请注明出处:作者:ZobinHuang,更新日期:Sept.23 2022

本作品由 ZobinHuang 采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,在进行使用或分享前请查看权限要求。若发现侵权行为,会采取法律手段维护作者正当合法权益,谢谢配合。
目录
有特定需要的内容直接跳转到相关章节查看即可。
前言
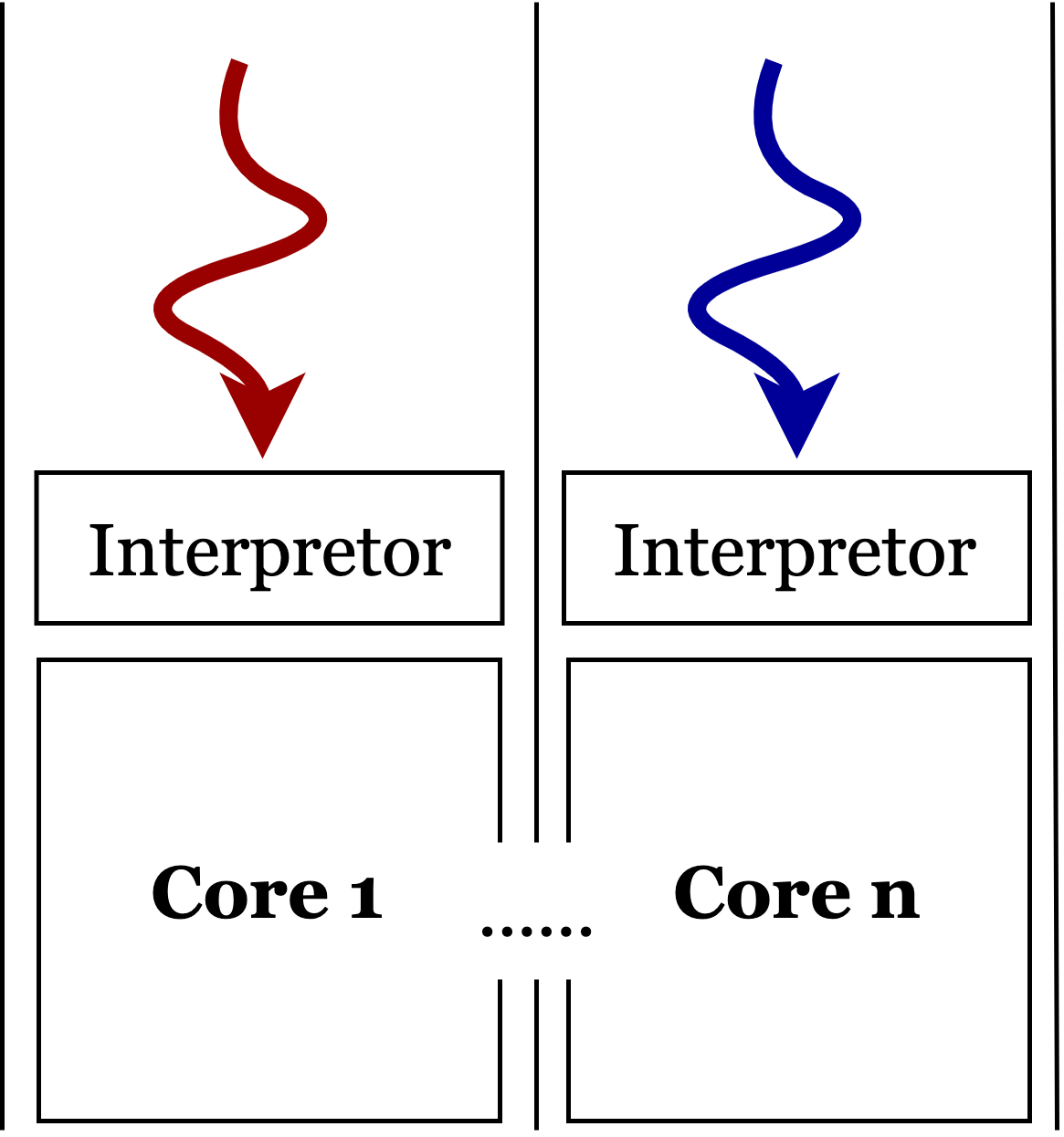
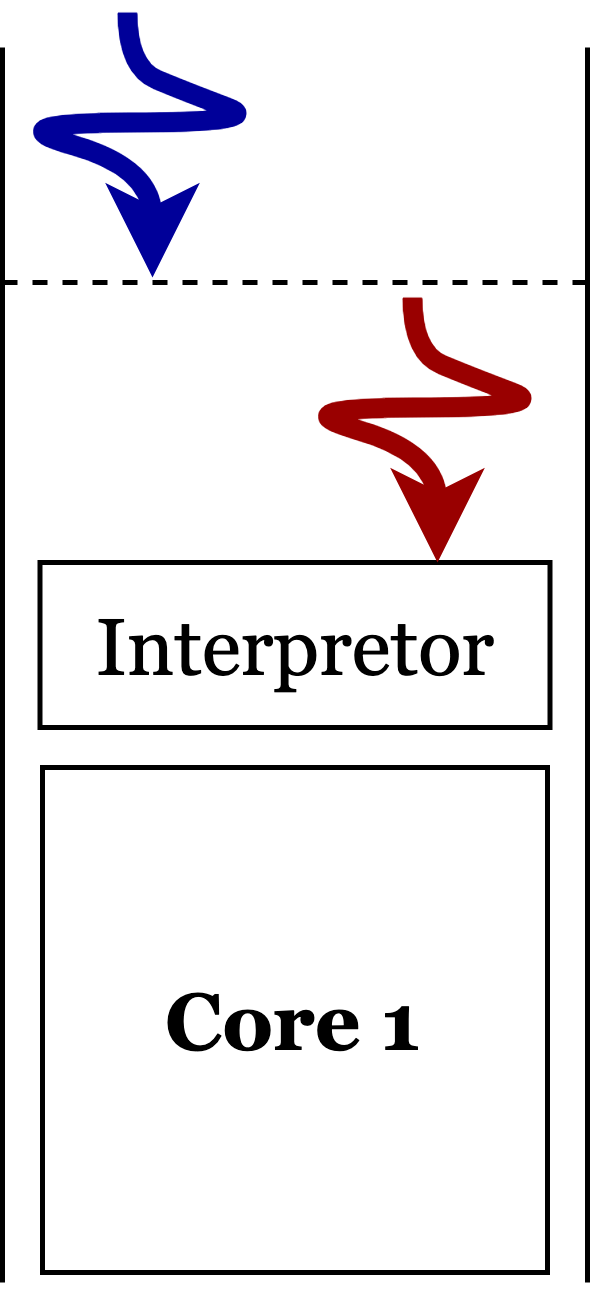
在 Python 中,我们可以基于 thread 模块实现所谓 thread 实现的所谓多线程实际上是伪多线程。如
在 Python 中要实现真正的程序并行运行,我们需要基于 multiprocessing 模块实现 fork() 或者 spawn() 系统调用实现进程上下文的自我复制,如
在本文中,我们介绍 Python 中基于 multiprocessing 模块的多进程相关特性。
多进程的创建和运行
首先我们来看如何创建多进程,这里介绍两种方式: ① 手动创建子进程和 ② 进程池。
手动创建子进程
1 | # 子进程程序 |
如上代码所示,展示了利用 Process 手动创建子进程的过程。这里有一个 Trick 是,Python 多进程程序的一个良好编程习惯是把主进程相关的逻辑都塞在一个函数中 (i.e. 在上面的代码中即 main_process),然后在对 __name__ 的 if 判断中调用该函数,原因是因为我们不想让子进程运行不属于它的代码。当我们运行上面这个程序的时候,它 __name__ =='__main__',因此它会执行 if 判断中的代码,这些代码会创建新的多个子进程,而这些子进程运行的程序 (i.e. child_function) 也位于当前这个模块中。在被调用的子进程中,它的 __name__ 不等于 __main__,因此它只会执行被主进程分配的任务 (i.e. child_function),而不会像主进程一样执行 if 判断中的代码 python_entrance。
进程池
1 | import time |
如上所示,我们也可以基于 Pool 类,基于进程池的方式来创建多个子进程。
两种创建进程的模式 —— fork 和 spawn
Python 多进程有两种创建进程的模式,1
2multiprocessing.set_start_method('spawn') # default on WinOS or MacOS
multiprocessing.set_start_method('fork') # default on Linux (UnixOS)
对于 fork 模式,主进程会直接自我复制给子进程运行,并把自己所有资源的 Handle 都让子进程继承,因而创建速度很快,但更占用内存资源。
对于 spawn 模式,主进程只会把必要的资源的 Handle 交给子进程,因此创建速度稍慢。
进程间通信
Pipe
1 | import time |
对于进程之间的通信,我们可以使用的方案之一即 Pipe() 所得到的两个返回值。我们上面的代码演示了两个子进程分别拥有 Pipe 的一端并实现通信的过程。上面代码的运行结果如下所示:
1
2
3$ python3 ./mp.py
I2 Recv: message from I1
I1 Recv: message from I2
通常来说,Pipe 是双向的,两端可以同时放进去东西,放进去的对象都经过了深拷贝:用 conn.send() 在一端放入,用 conn.recv() 从另一端取出。Pipe 的两端可以同时给多个进程,但是数据在 Pipe 中有且只有一份,当一份数据在某个进程中被接收后,其他进程就无法接收这份数据了。例子如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69import time
# 子进程程序: 两发两收
def func_pipe1(conn, p_id):
print(f'Process {p_id} created')
# 第一次发
time.sleep(0.1)
send_message = '{} message 1'.format(p_id)
conn.send(send_message)
print(f'Process {p_id} send: {send_message}')
# 第二次发
time.sleep(0.1)
send_message = '{} message 2'.format(p_id)
conn.send(send_message)
print(f'Process {p_id} send: {send_message}')
# 第一次收
time.sleep(0.1)
recv_message = conn.recv()
print(f'Process {p_id} recv: {recv_message}')
# 第二次收
time.sleep(0.1)
recv_message = conn.recv()
print(f'Process {p_id} recv: {recv_message}')
# 子进程程序: 一发一收
def func_pipe2(conn, p_id):
print(f'Process {p_id} created')
# 第一次发
time.sleep(0.1)
send_message = '{} message 1'.format(p_id)
conn.send(send_message)
print(f'Process {p_id} send: {send_message}')
# 第一次收
time.sleep(0.1)
recv_message = conn.recv()
print(f'Process {p_id} recv: {recv_message}')
def run__pipe():
from multiprocessing import Process, Pipe
conn1, conn2 = Pipe()
process = [
Process(target=func_pipe1, args=(conn1, 'I1')),
Process(target=func_pipe2, args=(conn2, 'I2')),
Process(target=func_pipe2, args=(conn2, 'I3')),
]
[p.start() for p in process]
# 主进程发送
send_message = 'Main message'
conn1.send(send_message)
print(f'Main process send: {send_message}')
# 主进程接收
recv_message = conn2.recv()
print(f'Main process recv: {recv_message}')
[p.join() for p in process]
if __name__ =='__main__':
run__pipe()
上面这份程序的运行结果如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14$ python3 ./mp.py
Process I1 created
Process I2 created
Main process send: Main message
Main process recv: Main message
Process I3 created
Process I1 send: I1 message 1
Process I2 send: I2 message 1
Process I3 send: I3 message 1
Process I1 send: I1 message 2
Process I2 recv: I1 message 1
Process I3 recv: I1 message 2
Process I1 recv: I2 message 1
Process I1 recv: I3 message 1
上面的程序证明了基于一条 Pipe 实现超过两个进程之间通信的可行性,然而在多生产者多消费者的情景下,还是推荐使用我们下一个小节介绍的 Queue 来实现,上面的程序是不推荐的形式。而如果程序追求进程间通信的性能的话,程序应该尽量使用本节介绍的 Pipe,而不是 Queue pipe_queue。
Pipe 的 duplex 参数在默认情况下值为 True,代表开启双向管道。若不开启双向管道,那么传数据的方向只能 conn1 $\leftarrow$ conn2。
若 Pipe 的 conn.poll() 方法返回值为 True,则其意味着可以马上使用 conn.recv() 拿到传过来的数据。而 conn.poll(n) 会让它等待 $n$ 秒钟再进行查询。例子如下所示:
1
2
3
4
5
6
7
8
9from multiprocessing import Pipe
# 开启双向管道,管道两端都能存取数据。默认开启
conn1, conn2 = Pipe(duplex=True)
conn1.send('A')
print(conn1.poll()) # 会 prin t出 False,因为没有东西等待 conn1 去接收
print(conn2.poll()) # 会 print 出 True ,因为 conn1 send 了个 'A' 等着 conn2 去接收
print(conn2.recv(), conn2.poll(2)) # 会等待2秒钟再开始查询,然后 print 出 'A False'
Queue
Queue 的功能与前面的管道 Pipe 非常相似:① 无论主进程或子进程,都能访问到队列;② 放进 Queue 的对象都经过了深拷贝。不同的是 Queue 可以实现基于 FIFO 的进程间队列通信,在多生产者多消费者的情况下,Queue 是 Python 推荐的多进程通信方案 pipe_queue。简单实例代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
for value in ['A', 'B', 'C']:
print(f'Put {value} to queue...')
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
while True:
if not q.empty():
value = q.get(True)
print(f'Get {value} from queue.')
time.sleep(random.random())
else:
# 强行终止
break
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 等待pw结束:
pw.join()
# 启动子进程pr,读取:
pr.start()
pr.join()
上面程序的运行结果如下所示:
1
2
3
4
5
6
7$ python3 ./mp.py
Put A to queue...
Put B to queue...
Put C to queue...
Get A from queue.
Get B from queue.
Get C from queue.
更多关于 Queue 的内容可以参考 pipe_queue。
共享内存
为了基于 Python 实现多进程通信,上面提及的 Pipe 和 Queue 把需要通信的信息从内存里深拷贝了一份给其他线程使用,需要分发的线程越多,其占用的内存越多,而本节介绍的
在 multiprocessing 模块中,基于 Manager 类可以创建一块共享的内存区域,但是存入其中的数据需要按照特定的格式;在 multiprocessing.sharedctypes 模块中,Value 类可以保存数值,Array 类可以保存数组。
下面是一个简单的例子,来自 Python 官方文档 pythondoc_mp。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36from multiprocessing import Process, Lock
from multiprocessing.sharedctypes import Value, Array
from ctypes import Structure, c_double
class Point(Structure):
_fields_ = [('x', c_double), ('y', c_double)]
# 子进程程序
def modify(n, x, s, A):
n.value **= 2
x.value **= 2
s.value = s.value.upper()
for a in A:
a.x **= 2
a.y **= 2
# 主进程程序
def main_process():
lock = Lock()
n = Value('i', 7)
x = Value(c_double, 1.0/3.0, lock=False)
s = Array('c', b'hello world', lock=lock)
A = Array(Point, [(1.875,-6.25), (-5.75,2.0), (2.375,9.5)], lock=lock)
p = Process(target=modify, args=(n, x, s, A))
p.start()
p.join()
print(n.value)
print(x.value)
print(s.value)
print([(a.x, a.y) for a in A])
if __name__ == '__main__':
main_process()