⚠ 转载请注明出处:作者:ZobinHuang,更新日期:July 7 2021

本作品由 ZobinHuang 采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,在进行使用或分享前请查看权限要求。若发现侵权行为,会采取法律手段维护作者正当合法权益,谢谢配合。
在本文中我们将主要讲解 8086 汇编编程中的寄存器和常用指令用法及其背后的硬件原理。
1. 寄存器的本质
2. 通用寄存器
在 8086 中有四个通用的 16-bits 寄存器:`AX`, `BX`, `CX`, `DX`。它们分别有可以被拆分为两个 8-bits 寄存器,即:
- `AX = AH+AL`
- `BX = BH+BL`
- `CX = CH+CL`
- `DX = DH+DL`
操作寄存器的基础命令如下:
1
2
3
4# 把 BX 中的值与 AX 的值相加并存放于 AX 中
add ax, bx
# 把 BX 中的值与赋与到 AX 中
mov ax, bx
有以下几个值得注意的点:
- 使用 "add", "mov" 命令操作寄存器时,注意操作数和被操作数的位数必须保持一致!
- 寄存器之间是相互独立的,比如 "add" 命令操作过后若在 AL 上产生了一个超过 8-bits 的结果,溢出的结果不会影响 AH,该结果会被截断放在 AL 上
2. 用于访问内存的寄存器
2.1 分段机制的 Motivation
由于 8086 CPU 在物理设计上有 20 根地址线 (i.e. 最大 `2^20 = 1MB` 的寻址空间),但是 CPU 内部的寄存器的最大位数只有 16 位,而用于寻址的寄存器的宽度决定了寻址能力,所以必须设计一种机制来使得 8086 CPU 拥有 1M 的寻址能力,这就有了分段机制。
在 8086 内部设计了一个地址加法器,使得最终的物理地址可以使用下面的方式被计算出来:
2.2 让 CPU 区分内存中的「指令」与「数据」
在内存中,不论是指令还是数据,都是以字节为单元的二进制信息进行存储,并没有区别。然而对于 CPU 来说必须在区分出两者的区别。因此 8086 使用了如下的方法。
(1) 获取指令
为了从内存中获取「指令」,8086 CPU 把 CS(Code Segment): IP(Instrucment Pointer) 指向的内存地址当作获取到的指令。整体的流程如下:
- CPU 从 CS:IP 指向的内存单元中读取指令,存放到指令缓存器中
- IP = IP+所读指令长度,从而指向下一条指令
- 执行指令缓存器中的内容,回到第一步
具体例子如下所示:
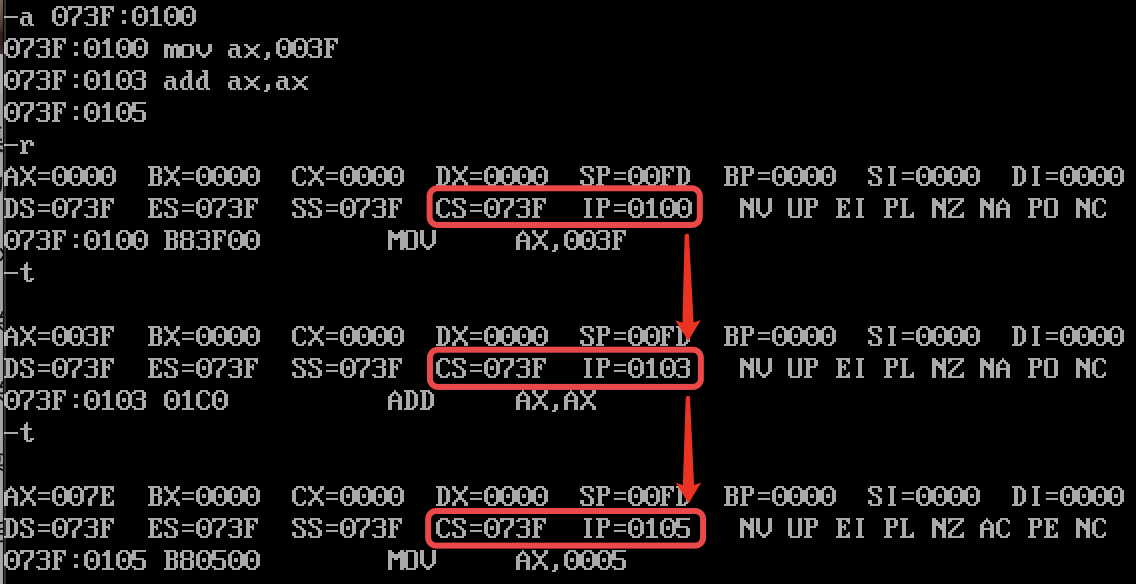
注意!8086 CPU 不允许我们使用 mov 命令来修改 CS:IP 中的值。
另外,如果在运行指令的过程中遇到了 "jmp" 指令,则 CS:IP 会被赋值为 "jmp [段基地址]:[偏移地址]" 后跟随的操作数的值,实现指令的跳转功能。"jmp" 指令也有 "jmp [寄存器]" 的形式,代表着 IP 寄存器会被 "jmp" 指令赋值为操作数寄存器的值。
"jmp" 指令的效果如下图所示:

"loop" 指令也可以用于跳转指令,实现了一种限制次数的循环机制。当 CPU 碰到 LOOP 指令时,其运行的过程是:
- CX 自减:CX = CX-1
- 循环判断:若 CX 不为 0,则跳转到 LOOP 后的操作数所指示的内存地址继续执行;若 CX 为 0,则运行 LOOP 后的语句。
"loop" 指令的效果如下图所示:
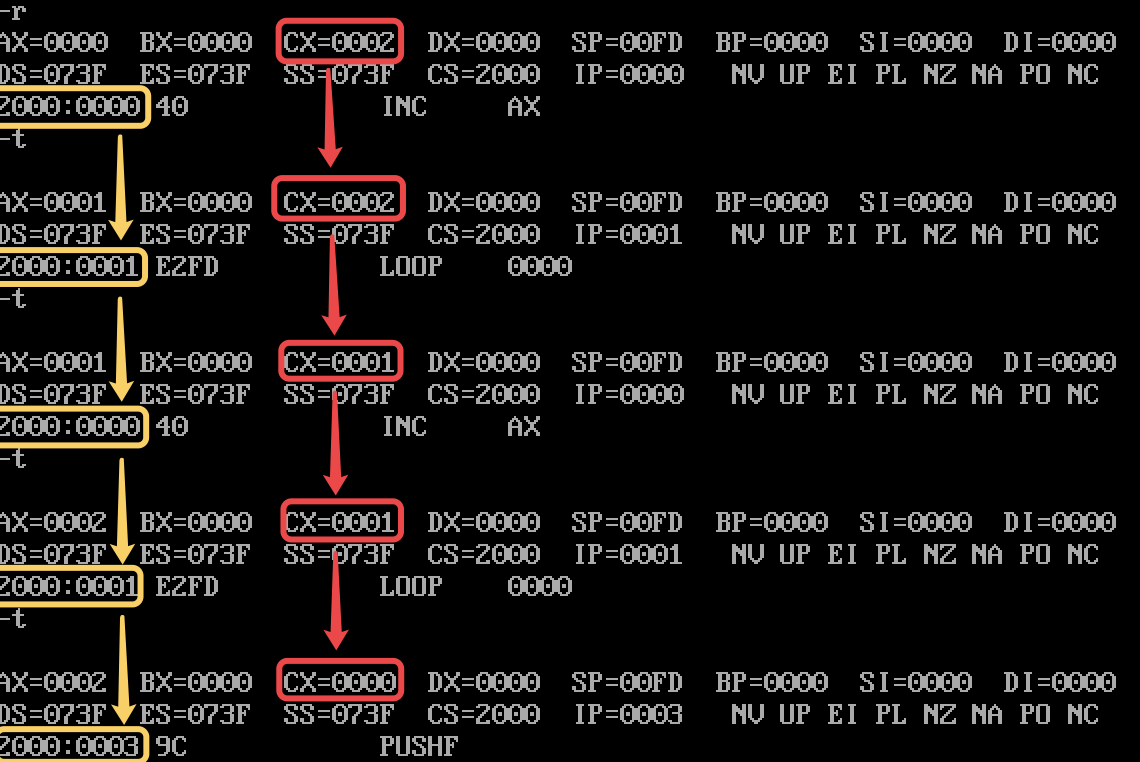
一个 loop 指令的例子
[这个问题建议看完下面的内容之后再回来思考] 将内存 FFFF:0 ~ FFFF:F 内存单元中的数据复制到 0:0200 ~ 0:020F 中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 # 设置数据从哪里来
mov ax, 0FFFFH
mov ds, ax
# 设置数据到哪里去
mov ax, 020FH
mov es, ax
# 设置数据偏移寄存器
mov bx, 0
# 设置循环次数
mov cx, 16
#开始循环
set_number: mov dl, ds:[bx]
mov es:[bx] dl
inc bl
loop set_number
(2) 获取数据
首先,我们必须知道,在内存中,数据和指令一样,也是按照以字节为单位的二进制信息存储的。对于 8086 CPU 来说,其看待内存中的字型数据 (16-bits)的顺序是:高地址存放高字节,低地址存放低字节,即小端模式。例子如下所示:

8086 CPU 使用 DS(Data Segment) 寄存器用于指示内存中的数据内容的段基地址,我们在汇编指令中只需要使用形如 "mov ax, ds:[0010]" 的指令,就可以将 DS:0010 处的数据读取到 AX 寄存器中。例子如下图所示:
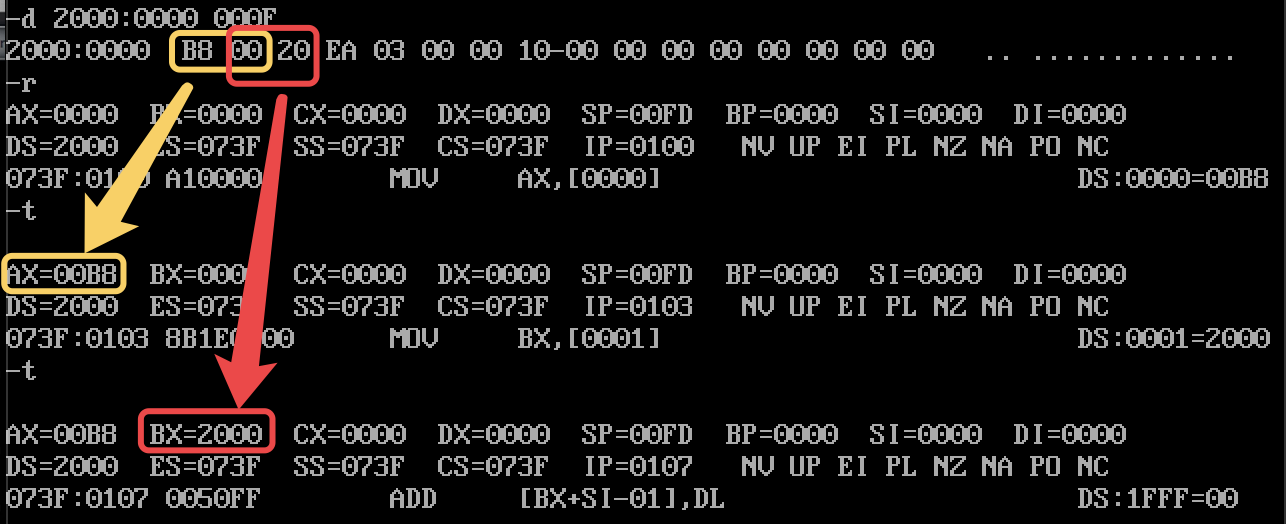
反过来,我们也可以使用形如 "mov ds:[0010], ax" 的指令,把 AX 寄存器中的值赋给 DS:0010 指向的内存单元中。 如下图所示:
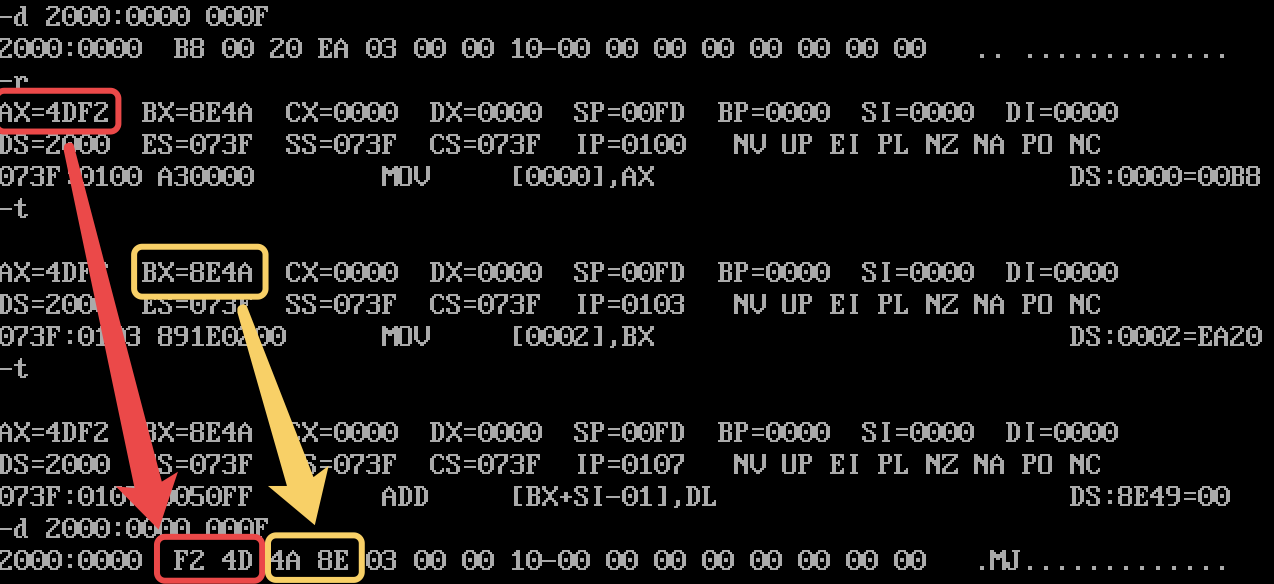
另外值得注意的是,8086 CPU 不支持直接使用 "mov" 指令直接修改 DS 寄存器中的值,我们必须采用间接的方法 (e.g. mov ds, ax) 来对其进行赋值。
我们也可以把寄存器 BX 当作偏移地址寄存器,通过把偏移地址写入 BX 寄存器,然后使用形如 "mov ds:[bx], ax" 等形式来访问内存中的数据。另外,SI 和 DI 寄存器也可以供我们用于访问 DS 所指示的数据段内存,如 "mov ax, ds:[bx+si]", "mov ds:[bx+di], ax", "mov ax, ds:[bx+8]", "mov bx, ds:[bx+si+8]" 这样的内存访问形式都是允许的。
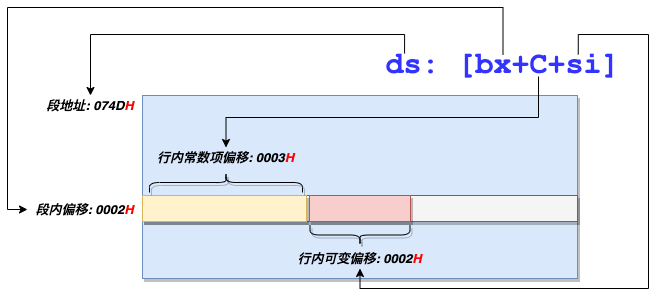
读者可能会有疑惑,为什么要这么复杂地去定位内存呢?上图应该能解答这个疑惑:DS 寄存器用于锁定是哪个段,BX 寄存器用于锁定是段内的哪一行,常数用于设置常数项行内偏移,SI/DI 用于设置可变的行内偏移。这里实际上是体现了偏移的思想。我们在写汇编程序的时候,最重要的一件事情就是去观察数据在内存中的分布情况,然后选择一种合适的访问内存的方式去操作数据。
在 8086 CPU 中,ES 寄存器有着和 DS 寄存器一样的功能,即指向内存中存储数据的段的基地址。
(3) 以 "栈" 的形式访问内存
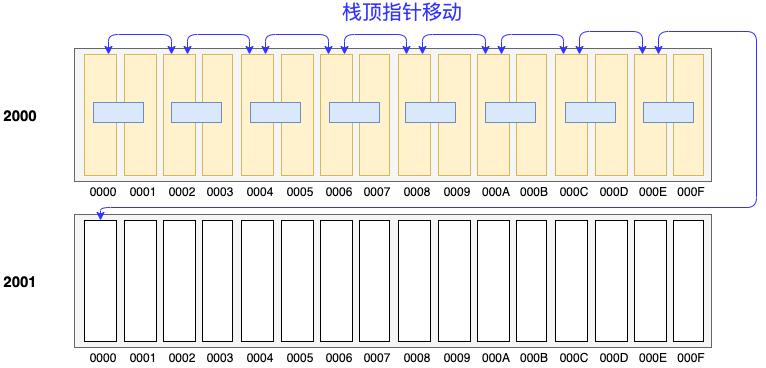
8086 CPU 在任意时刻 将 SS(Stack Segment) 和 SP(Stack Pointer) 所指向的内存单元当作栈顶标记,出栈和入栈的操作都基于这个栈顶标记来进行。注意出栈和入栈操作仅可对字型数据进行操作(i.e. 一次性 2 个字节)。栈顶标记的移动过程可以用上图来说明,黄色部分是我们想要以栈的形式访问的内存,蓝色线条是栈顶标记的移动过程,其过程如下所述:
对于入栈指令 "push ax":
- 移动栈顶指针:修改 SP 寄存器中的数值为 SP = SP-2
- 将 AX 中的字型数据,存放到 SS:SP 所指向的内存单元中
对于出栈指令 "pop ax":
- 将 SS:SP 所指向的内存单元中的数据存放到 AX 寄存器中
- 移动栈顶指针:修改 SP 寄存器中的数值为 SP = SP+2
"push" 和 "pop" 指令导致的 SS:SP 具体的变化过程如下所示:
值得注意的是 "push" 和 "pop" 操作都是有可能导致栈访问越界的,因此我们在对栈进行操作的时候应该十分小心。
栈的应用有很多,其中一个最关键的就是可以用于临时保存变量,思考下面一个嵌套循环的例子,为了实现双重循环,必须临时保存存储循环次数的寄存器 CX 的值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14# if interested: 这段代码实际上完成了将一个多行ASCII 数据中每行的前 4 个字母转化为大写字母的功能
up_row: push cx
mov cx, 4
mov si, 0
up_letter: mov al, ds:[bx+si]
and al, 1101111B
mov ds:[bx+3+si], al
inc si
loop up_letter
pop cx
add bx, 16
loop up_row
另外,还有一个寄存器 BP(Base Pointer),它经常被用于遍历栈中的数据。我们知道 SS 和 SP 寄存器是不能被随意修改的,因为它们决定了栈顶指针的位置。因此当我们要遍历栈中的数据时,我们可以 mov bp, sp 之后,使用 BP 来作位移遍历栈中的数据。
3. 如何在汇编中完成除法操作?
首先,在之前的编程中,我们都是让程序根据操作的寄存器位数自动判断我们的操作数是 8-bits 的还是 16-bits 的,如使用 "mov ax, 0FH" 的话 "0FH" 就会被翻译为 "000FH" 的 16-bits 数据。考虑 "mov ds:[0], 0FH",这样的话 CPU 会怎样对待 "0FH" 呢?似乎不可控。8086 汇编提供了一些关键字用于显式地指出指令操作数的宽度: "byte ptr" 和 "word ptr"。如 "mov byte ptr ds:[0], 0FH" 指令就会把 "0FH" 当作一个字节看待,"mov word ptr ds:[0], 0FH" 指令则会把 "0FH" 当作 "000FH" 看待。
现在我们给出 8086汇编实现除法的过程。首先我们看数据存储的位置:
除数有 8-bits 和 16-bits 两种,可以放在某个不冲突的寄存器或者内存单元中。
而对于被除数,存放位置如下:
| 除数位数 | 被除数位数 | 被除数存放位置 |
|---|---|---|
| 8-bits | 16-bits | 默认在 AX 中 |
| 16-bits | 32-bits | 默认 DX 存放高 16 bits,AX 存放低 16 bits |
对于商和余数:
| 除数位数 | 商存放位置 | 余数存放位置 |
|---|---|---|
| 8-bits | 默认在 AL 中 | 默认在 AH 中 |
| 16-bits | 默认在 AX 中 | 默认在 DX 中 |
其次,我们进行除法操作使用的指令是 "div 除数",其中除数可以用寄存器或者内存单元来表示,并且可以配套我们上文介绍的 "byte ptr" 和 "word ptr" 来指定除数的宽度。
细心的读者可能会发现,假如我们使用 32-bits 的被除数 "1FFFFH" (AX="FFFFH", DX="0001H") 去除以一个 16-bits 的数 1,那么结果将会是 "1FFFFH",根据上表这个商应该被存储在 AX 中,但是很明显放不下,因此就会造成错误。这是 CPU 除法机制设计下的 "除溢出 (Divide Overflow)" 问题。
4. 如何在汇编中完成乘法操作?
上面一小节我们讲了 8086 中实现除法操作的做法,这一小节我们介绍实现乘法操作的做法。
乘法操作使用的命令是 mul。两个想成熟,要么都是 8 位 (8 位乘法),要么都是 16 位 (16 位乘法)。如果是 8 位乘法,那么一个数字默认存放在 AL 寄存器中,另一个数字存放在其它 8 位寄存器或者字节型内存单元中;如果是 16 位乘法,那么一个数字默认存放在 AX 寄存器或者字型内存单元中,另一个数字存放在其它 16 位寄存器中。mul 命令的形式如下:
mul ah
mul byte ptr ds:[0]
mul ax
mul word ptr ds:[0]
8 位乘法会得到一个 16 位数值,存放在 ax 中;16 位乘法会得到一个 32 位数值,低 16 位存放在 ax 中,高 16 位存放在 dx 中。
5. 寄存器总结
这里对上述所有 8086 CPU 的寄存器作出总结
| 名称 | 类型 | 作用 |
|---|---|---|
| AX, BX, CX, DX | 16-bits 通用寄存器 | 可用于存储各类数据,其中 BX 常用于存储内存偏移量 DS:[BX],CX 常用于控制 loop 次数,AX 和 DX 寄存器则常用于存储 16-bits 除法操作的 32-bits 被除数 |
| AL&AH, BL&BH, CL&CH, DL&DH |
8-bits 通用寄存器 | 可用于存储各类数据,其分别是 AX, BX, CX, DX 的高低八位 |
| CS:IP | 16-bits 代码段基地址:段指针寄存器 | 用于指示代码段位置 |
| DS, ES | 16-bits 数据段基地址寄存器 | 用于指示数据段基础位置 |
| SS:SP, BP | 16-bits 栈段基地址:段指针寄存器,以及栈基指针寄存器 | SS:SP 用于指示栈段基础位置,BP 用于遍历栈中数据使用 |
| SI, DI | 16-bits 数据段偏移寄存器 | 常用于在访问数据段内存时,控制偏移地址 |